My GitHub Repository has 100,000 Contributors
Published • 10 min read • more posts
Table of Contents
What?
Your eyes don’t deceive you. You can check right now: my GitHub repository has 100,000 contributors. If you are on GitHub mobile, the number may not appear. You have to view this repository through GitHub’s web UI.
Before I explain the why and the how, we first need to go back to a few weeks ago. I was routinely moving around some configuration files, and I accidentally swapped my ~/.gitconfig file with that of my alternate account. When I pushed to one of my repositories, I was surprised to notice that my alt account was added as a contributor! Its rendered profile picture, username, and hyperlink — all neatly displayed under “Contributors”.
There’s a good chance you’ve already seen something similar to this; it isn’t hard or particularly new to fake a commit from another user. But my curiosity was sparked. In my mind, the next logical question to ask was: how many contributors could I fake? And thereafter: could I get to exactly 100,000 contributors? It would be a fireplace of ghosts, a bizarre pit stop of GitHub users.
(Before continuing, I would like to point out that users can sign their commits to cryptographically verify their identity, ineffectuating impersonation. Even then, impersonation is against GitHub’s Acceptable Use Policies. Please be wary.)
I wasn’t trying to make 100,000 commits faking a different user each time, so I did some research and found a more efficient way. If you add two new lines under a commit message, you can co-author users with their username and email address as shown.
~ % git commit -m "Refactor usability tests.
>
>
Co-authored-by: NAME <[email protected]>
Co-authored-by: ANOTHER-NAME <[email protected]>"And so on, with seemingly no co-author limit. Luckily for my case, each one is added as a contributor! Armed with this knowledge, I began to formulate a plan.
The plan
Manually adding this many users to a commit message obviously isn’t practical. I needed to write an API scraper, and a quick check of GitHub’s policies affirms I’m allowed to do this provided that I’m not excessive.
We do allow the use of automated tools so long as they do not produce excessive amounts of traffic. For example, running one nmap scan against one host is allowed, but sending 65,000 requests in two minutes using Burp Suite Intruder is excessive.
So, I got to brainstorming. The most important conceptual hurdle was figuring out how to get a user’s email address, as you can’t co-author a user without it. The problem was, even if a user makes their email address address publicly visible on their profile, the GitHub API doesn’t reliably expose it1. Surprisingly, there is a very well-known way to circumvent this and find almost anyone’s email address on GitHub.
Simply navigate to any commit authored by a user on GitHub and append .patch to the commit’s url. Et voilà! The second line from the top enclosed within angled brackets lies their email address, in full form and glory. It sounds concerning that this type of information is so easy to access, but if you think about it, emails are made public for a reason. Attribution and contact are pretty important from an open source perspective.
With these types of technical projects that work with big data, social conduct should be taken seriously. I don’t want to end up in a similar situation as this guy and piss off 100,000 people by publicly leaking their email addresses. So, I decided to only co-author private email addresses that are only valid within GitHub.
Admittedly, a small amount of real email addresses were committed at the beginning, but only for testing purposes. I believe that this amount is small enough to be insignificant and inconsequential.
How would I find 100,000 users? GitHub provides a Search API for querying for users, but this was problematic because it had a rate limit of… wait for it… 30 requests per hour. Ba dum, tss! Instead, I opted to use the API endpoint for followers to feed my scraper its users, which had a more reasonable rate limit I could work with.
Putting everything together, my API scraper will:
- First use the Search API to find the most followed users on GitHub
- Use the followers API endpoint to loop through each user’s followers (In retrospect, another approach could be utilizing a web crawling algorithm)
- Use the “hack” as described earlier to find each follower’s email address
- Filter each email address for private email addresses and format the co-author message
Hopefully you can see that, through some intuitional ingenuity, the idea no longer sounds as Herculean a task as it seems.
The script
I decided to write the scraper in JavaScript so I could utilize octokit.js, an API wrapper that provides useful built-in functionality such as throttling and retrying. I also decided to use GitHub’s GraphQL API instead of their REST API because multiple GraphQL queries could be batched in a single request and other smaller efficiencies.
After hacking up a prototype, I tested my first commit.

It works!
I would spend the next week polishing response edge cases and ironing out inefficiencies, before I was finally ready to run my scraper.
I didn’t feel like running it locally because I knew from testing it would take a long time. Instead I bought a DigitalOcean VM, imported my script, and ran it as a background process.
:~# git clone https://github.com/ArhanChaudhary/everyone
:~# cd everyone
:~/everyone# nohup node index.mjs --co-author-count=100000 > results.txt 2> log.txt &
[1] 104705I think it’s worth mentioning how surprisingly lenient the GraphQL API rate limits are, given how notoriously restrictive the Rest API rate limits are. Even though my scraper was continuously and asynchronously parallelizing multiple batched queries at once, the highest I ever saw the GraphQL hourly rate limit quota reach was 1,500 out of 5,000 points.
Nine hours later, combing through approximately half a million GitHub users, my scraper yielded 100,000 co-authors, each ready to become a contributor. Hooray!
I’m so sorry if it feels like I’m cutting you off, but I first wanted to discuss a few API anomalies on the error log before we get to the committing. Trust me, what I’ve found is equally, if not more interesting.
The mystery of U_kgDOAMbr8w
Out of those half a million users, exactly two of them always crash the GraphQL API. That’s a 0.0004% fallthrough rate. Following some investigation, I was able to narrow down the crashing to any valid query containing the substring history(author: {id: "..."}), where the id parameter is either of their GraphQL user IDs. If you want to try yourself, execute this on the GitHub GraphQL explorer:
query {
repository(owner: "torvalds", name: "linux") {
defaultBranchRef {
target {
... on Commit {
history(author: {id: "U_kgDOAMbr8w"}) {
totalCount
}
}
}
}
}
}It doesn’t matter which repository you specify, the results are the same.
I emailed both users to inquire about anything they might know about this issue. The second user responded, equally as puzzled as I was. After exchanging Discords, we spent a few hours discussing theories and possible security concerns, but despite our research we weren’t able to come to a conclusion. I ultimately ended up filing a bug report to GitHub support.
I would receive this response.
Hi Arhan,
Thanks for reaching out!
I was able to reproduce the error and it seems the bug is related to some odd author information associated with user accounts.
I have filed an internal issue with the engineering team to look into this bug. While I don’t have an ETA on a fix now, we appreciate you reaching out on how we can make things better.
…
The mystery of MyWebsite
Have you ever seen a corrupted repository?
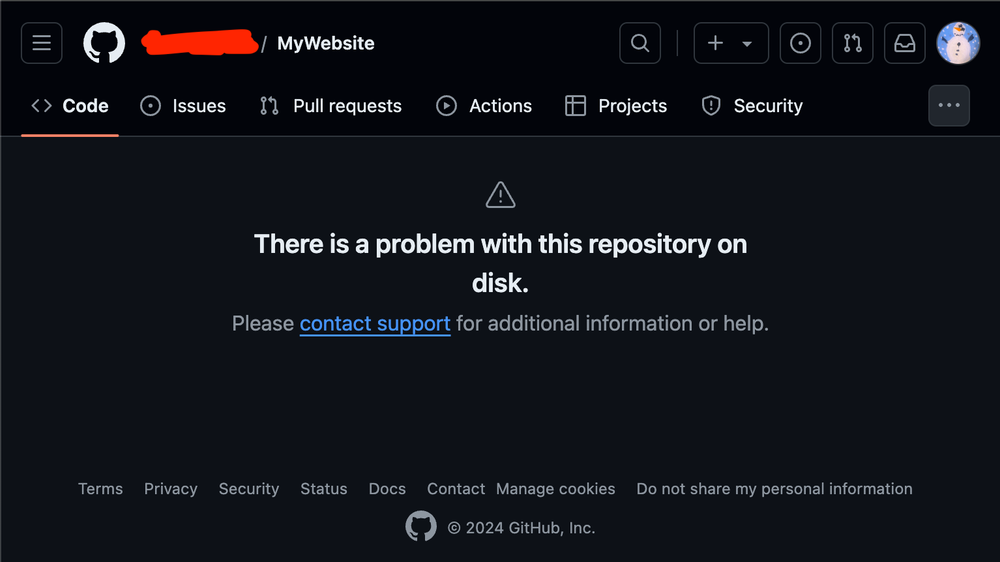
Well, it ended up crashing my script half way through. Having to re-run it was more annoying than it should have been.
It turns out you can still clone this repository. Inspecting the commit history presents something interesting.
Desktop % git clone https://github.com/.../MyWebsite.git
Desktop % cd MyWebsite
MyWebsite % git log -n 1
...
Date: Fri Dec 2 10:14:22 3194 +25627400
...From a prior CTF competition, I already knew that GitHub was perfectly fine with future commit dates. I wasn’t sure why this was happening, so I replicated this commit on a test repository.
Test % git commit --allow-empty -m "Testing"
Test % commit=$(git rev-parse HEAD)
Test % git cat-file commit $commit > commit.txt
Test % vim commit.txt # change both timestamps to 38654734462000 +25627400
Test % new_commit=$(git hash-object -t commit -w commit.txt)
Test % git update-ref refs/heads/main $new_commit
Test % git pushThese commands only work on Git v2.38.2 or earlier, don’t ask me how I know that.
Sure enough, after pushing, my test repository also nuked itself in a similar fashion with the same error message. I was able to pinpoint this behavior to the invalid UTC offset on the commit date, a classic parsing oversight. I took this a step further and wanted to see what would happen if I opened a pull request referencing this commit. Feast your eyes on…
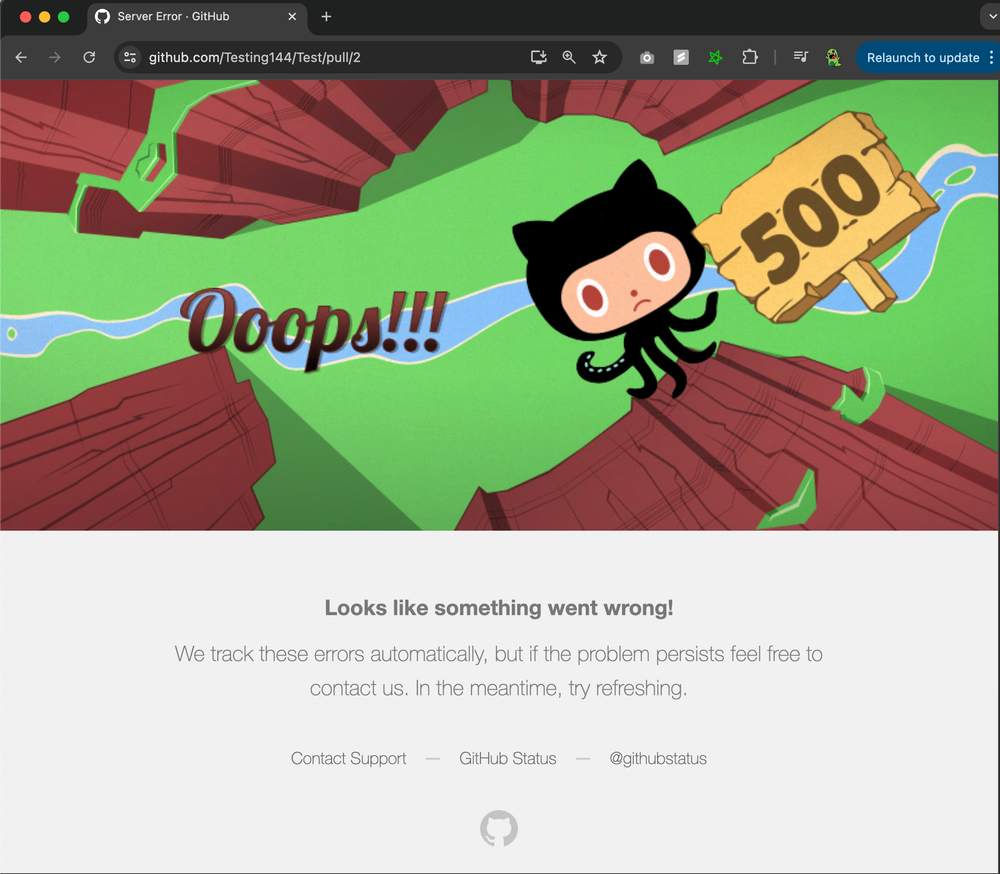
I really wish I could say I found a denial-of-service PoC and became $1,000 (or more) richer. Imagine how cool of a resolution that would sound! Like before, following triage with some of my friends, I surrendered empty-handed and filed a bug report to GitHub support.
I would receive this response two days later.
Hey Arhan,
Thanks for getting in touch and flagging this. I take it you’ve been exploring different ways to edit git commits manually and exploring how they behave on GitHub? :)
We’re not able to gracefully handle every possible sort of malformed/corrupted commit that might occur, as much as we’d like to.
Given the extensive steps required to achieve this outcome, it’s unlikely this would be encountered as part of regular work when collaborating on GitHub. Because of this, it’s unlikely that if I raised this with one of our engineering teams that it’d be picked up to be worked on/improved.
I hope you can understand why we’re not always able to work on all bug reports we receive, but if you identify a way this occurs as part of regular activity, please write back and let us know - we’d be happy to investigate further.
…
Understandable, but nevertheless interesting.
100,000 Contributors
Where were we? Oh right, apologies for the side-tangents, I tend to get distracted. Now that we have all of our co-authors, let’s get the party started!
everyone % scp [email protected]:everyone/results.txt .
everyone % echo -e "👀\n\n$(cat results.txt)" | git commit --allow-empty -F -
everyone % git push…
Thirty minutes later, nothing happens.
…
Uh oh.
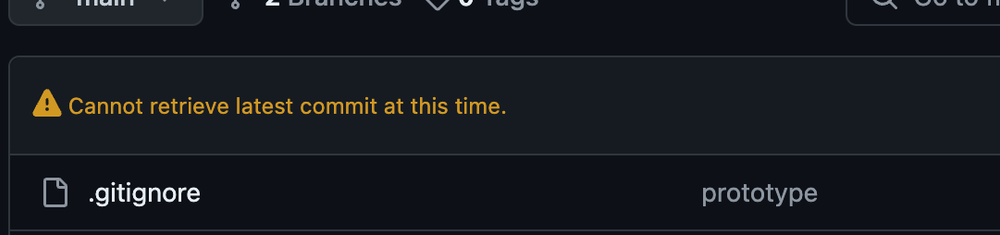
I’m just messing with you, it wasn’t that dramatic. After force git-resetting, simply splitting up the co-authors into commits of 5,000 at a time did the trick.
everyone.sh
#!/bin/bash
split -l 5000 -a 5 results.txt split_
FIRST_ITERATION=1
for i in split_*
do
if [ $FIRST_ITERATION -eq 0 ]; then
sleep 120
fi
FIRST_ITERATION=0
echo -e "👀\n\n$(cat $i)" | git commit --allow-empty -F -
git push
done
rm split_*
echo "Co-authors successfully processed!"After running the script, around half an hour later:
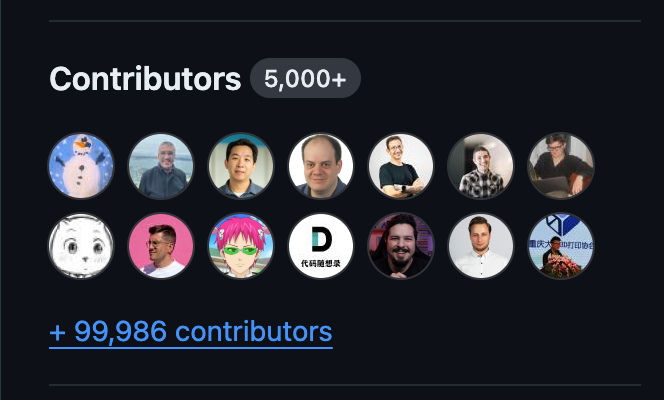
Tada! *drops mic*
Not bad for my second blog, don’t you think? Until next time!
Footnotes
-
The situation here is strange. For reasons unknown, the GitHub GraphQL API straight up doesn’t expose the majority of users’ public emails… UNLESS you use the GitHub REST API; in which case only this method works… UNLESS you use the GitHub GraphQL explorer which seems to work with the same level of accuracy. I know I’m not going crazy. It’s really weird. ↩