The Generativity Pattern in Rust
Published • 39 min read • more posts View on
This article was peer-reviewed by my close friends Henry Rovynak, Kartavya Vashishtha, Jack Hogan, Mikhail Khan and Crystal Durham. I thank them for their invaluable feedback. This article also uses special characters like the em-dash (—). These characters were lovingly hand-inserted and are not the result of AI-generated text.
Table of Contents
- Introduction
- Background
- The unsafe approach
- The atomic ID approach
- The generativity approach
- How does
generativitywork? - Benchmarks
- Conclusion
Introduction
The generativity pattern in Rust is a combination of typestate and GhostCell, techniques that move what you’d normally check at run-time to compile-time. This pattern is not commonplace; its usage warrants a specific set of circumstances. However, it is a hugely important part of garbage collection utilities and other niche Rust crates.
Aside from thinly spread academic literature1, I haven’t found an accessible analysis of this pattern online. In order to build up a full picture of the “what” and more importantly the “why,” we will first spend some time walking through a realistic example to gauge the type of problem the generativity pattern solves—statically requiring data to come from or refer to the same source—as a stronger form of ownership. Then, we will introduce the generativity pattern and explain how to use it in the latter half of this article. Finally, we will follow up with a study of Crystal Durham’s generativity crate, a novel improvement to the generativity pattern. Buckle up!
Background
Permutations
Let us take the role of a crate author about permutations. We want to investigate the composition of zero-indexed permutations. This can be expressed nicely visually.
The permutation b defines the remapping of the elements from permutation a. Pretty simple. Notice that permutation composition is only possible under the following three conditions:
aandbmust have the same length.- Every element from
aandbmust be non-negative and less than the length. - Every element from
aandbmust be unique.
Our library is general-purpose, so it is important to handle these error cases. Here is the simplest way to do that.
/// We provide a `compose_into` function in case the caller already
/// has a permutation preallocated. (This is good practice IMO).
pub fn compose_into(a: &[usize], b: &[usize], result: &mut [usize]) -> Result<(), &'static str> {
if a.len() != b.len() || b.len() != result.len() {
return Err("Permutations must have the same length");
}
let mut seen_b = vec![false; a.len()];
let mut seen_a = vec![false; b.len()];
for (result_value, &b_value) in result.iter_mut().zip(b) {
if *seen_b
.get(b_value)
.ok_or("B contains an element greater than or equal to the length")?
{
return Err("B contains repeated elements");
}
seen_b[b_value] = true;
let a_value = a[b_value];
if *seen_a
.get(a_value)
.ok_or("A contains an element greater than or equal to the length")?
{
return Err("A contains repeated elements");
}
seen_a[a_value] = true;
*result_value = a_value;
}
Ok(())
}Good on you if this made your Rust senses tingle because we shouldn’t have to validate a and b every time. Rust allows us to enforce at the type level that they are valid permutations, using the newtype design pattern.
pub struct Permutation(Box<[usize]>);
impl Permutation {
pub fn from_mapping(mapping: Vec<usize>) -> Result<Self, &'static str> {
// This function errors if `mapping` is an invalid
// permutation or its length does not match the second
// argument. The implementation is ommitted.
validate_permutation(&mapping, mapping.len())?;
Ok(Self(mapping.into_boxed_slice()))
}
pub fn compose_into(&self, b: &Self, result: &mut Self) -> Result<(), &'static str> {
if self.0.len() != b.0.len() || b.0.len() != result.0.len() {
return Err("Permutations must have the same length");
}
for (result_value, &b_value) in result.0.iter_mut().zip(&b.0) {
// SAFETY: `b` is guaranteed to be a valid permutation
// whose elements can index `self`
*result_value = unsafe { *self.0.get_unchecked(b_value) };
}
Ok(())
}
pub fn compose(&self, b: &Self) -> Result<Self, &'static str> {
let mut result = Self(vec![0; self.0.len()].into_boxed_slice());
self.compose_into(b, &mut result)?;
Ok(result)
}
}The newtype pattern is more useful than just for getting around the orphan rule. We restrict construction of Permutation to Permutation::from_mapping, which returns an error if the input is not a valid permutation. That means if we have an instance of Permutation, we don’t have to worry about its mapping being potentially invalid, reducing the validation overhead to a length check and permitting unsafe during permutation composition. Rustaceans describe type-level guarantees like this by saying an invariant of Permutation is that it represents a valid permutation. Composing two permutations upholds this invariant, so we expose Permutation::compose to create a new Permutation from existing ones.
This code is a major improvement! It is simple, easy to use, and it provides reasonable errors. However, a closer examination reveals some problems:
- Every call to our composition function spends time performing a length check. Our example is simplistic so it happens to be cheap, but this type of check may require more expensive logic in a practical scenario. Note that we can’t use const generic lengths because our library operates on arbitrarily-sized slices at run-time.
- Returning a
Resultforces the caller to be prepared to handle the error variant. Library users might be able to guarantee that the length checks will pass, which would make the error handling more annoying than helpful.
Yes, these aren’t important problems per se, but they are still inconveniences to be aware of.
Permutation groups
We now want to extend our library to model a permutation group, a description of a set of permutations. In a permutation group, every permutation in the set can be written as a sequence of compositions of a select few base permutations, which we will use to represent the entire collection. For example, the manipulations of the Rubik’s Cube form a permutation group. Its base permutations which represent the entire permutation group are the six face rotations. By definition, every possible state on the Rubik’s Cube can be reached from a combination of those face rotations.
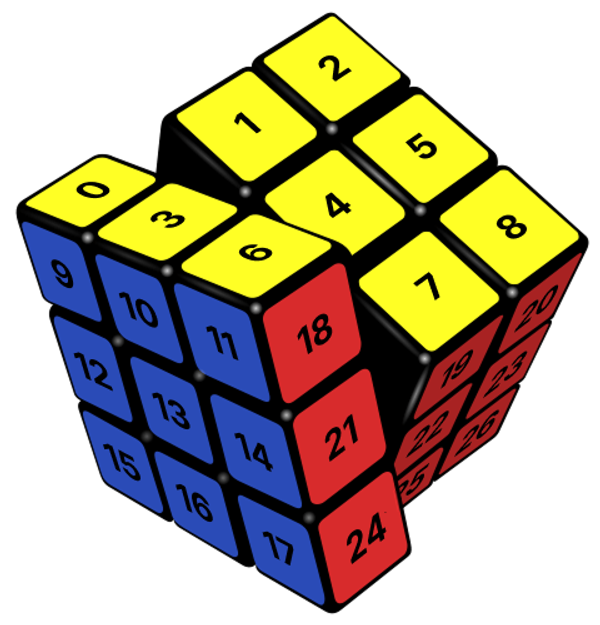
The illustrated turn is a permutation fifty-four elements long, because there are fifty-four stickers on a Rubik’s Cube2.
It follows that if you compose two permutations in a permutation group, the resulting permutation will also be a permutation in that group. The reasoning is not so relevant; take this at face value.
A reasonable data structure for permutation groups looks like this:
pub struct PermGroup {
base_permutation_length: usize,
base_permutations: Vec<Permutation>,
}
impl PermGroup {
pub fn new(
base_permutation_length: usize,
base_permutation_mappings: Vec<Vec<usize>>,
) -> Result<Self, &'static str> {
for mapping in &base_permutation_mappings {
validate_permutation(mapping, base_permutation_length)?;
}
Ok(Self {
base_permutation_length,
base_permutations: base_permutation_mappings
.into_iter()
.map(|mapping| Permutation(mapping.into_boxed_slice()))
.collect::<Result<Vec<Permutation>, &'static str>>()?,
})
}
pub fn base_permutations(&self) -> &[Permutation] {
&self.base_permutations
}
}Your inner Ferris awakens. With the annoyances of our last iteration freshly in memory, you ask yourself: can we perform that length check (the validate_permutation function) during the creation of PermGroup, and avoid it entirely in Permutation::compose_into? Then, can we tweak our composition function to only operate on permutations from the same permutation group?
impl Permutation {
// No `from_mapping` method. `Permutation` can only be
// constructed within `PermGroup::new`.
pub fn compose_into(&self, b: &Permutation, result: &mut Permutation) {
for i in 0..result.0.len() {
// SAFETY: ... ?
unsafe {
*result.0.get_unchecked_mut(i) = *self.0.get_unchecked(*b.0.get_unchecked(i));
}
}
}
pub fn compose(&self, b: &Permutation) -> Permutation {
let mut result = Self(vec![0; self.0.len()].into_boxed_slice());
self.compose_into(b, &mut result);
result
}
}All of a sudden, we’ve opened up an unsafety hole! We implicitly assumed that the permutations to compose were from the same permutation group. This is not necessarily true: what if a library user composes two base permutations from different permutation groups? If the permutation lengths don’t match, get_unchecked will index out of bounds and exhibit undefined behavior; this is clearly a problem! The intent of this operation is obviously nonsensical, but it does not change the fact that it is still our responsibility, as the crate author, that the safe functions we provide can never cause undefined behavior.
There is a more fundamental reason to care about this unsoundness if left unchecked. An invariant of permutation composition within the same permutation group is membership; if the permutations to compose are in the same permutation group, the resulting permutation is also in that group. Even if the lengths of permutations from two different permutation groups did match, composing them could produce a permutation outside of either group, which is a logic error. Other code may even have unsafe blocks that rely on permutation group membership, for example a Rubik’s Cube solver optimized for speed.
Mitigating this by checking permutation group membership every function call is a very expensive operation. This is an example of the “practical scenario” mentioned beforehand.
We have demonstrated that the newtype pattern alone is not powerful enough to prevent this logic error. We will analyze different approaches that ensure our library only permits permutation composition within the same permutation group. Each has their own trade-offs, but are all right answers for different situations. They will also lay the groundwork to justify using the generativity pattern.
All the code segments provided in this article can be found here.
The unsafe approach
The simplest solution is to mark Permutation::compose_into and Permutation::compose unsafe.
/// # Safety
///
/// `self`, `b`, and `result` must all be from the same
/// permutation group.
pub unsafe fn compose_into(&self, b: &Permutation, result: &mut Permutation) {
for i in 0..result.0.len() {
// SAFETY: permutations within the same group can be
// composed.
unsafe {
*result.0.get_unchecked_mut(i) = *self.0.get_unchecked(*b.0.get_unchecked(i));
}
}
}Although the extent of the undefined behavior with permutation composition is just the bounds checking, the goal of this approach is to enforce permutation group membership. Thus, the above safety contract is made more restrictive to reflect this idea. The usage of unsafe to maintain a validity invariant is contentious. Permutation composition of the same length within different permutation groups is a logic error, and it violates the safety contract, but is not technically unsafe. Sure, you might panic later on or get some other issue, but this alone will never cause undefined behavior.
To play devil’s advocate, since we only care about composition within the same permutation group, one may consider producing an invalid value from this type of permutation composition undefined behavior. With the safety contract’s additional restriction, calling code no longer has to worry about handling this logic error, while additionally gaining the contextual benefit of this assumption. Personally, I believe this use of unsafe is warranted—at the end of the day, the safety contract does still prevent undefined behavior. I encourage you to have your own opinion.
If you don’t care about using unsafe—and there are valid reasons not to—then this might be what you want. That said, it’s not always going to be this simple. What if we introduce a new trait, ComposablePermutation, that generalizes over different permutation representations? For example, the PSHUFB instruction can compose two permutations in a single clock cycle if they have less than sixteen elements.
pub trait ComposablePermutation: Clone {
fn from_mapping(mapping: Vec<usize>) -> Result<Self, &'static str>;
/// # Safety
///
/// `self`, `b`, and `result` must all be from the same
// permutation group.
unsafe fn compose_into(&self, b: &Self, result: &mut Self);
/// # Safety
///
/// `self` and `b` must both be from the same permutation
// group.
unsafe fn compose(&self, b: &Self) -> Self {
let mut result = self.clone();
// SAFETY: `self`, `b`, and `result` are all from the
// same permutation group.
unsafe { self.compose_into(b, &mut result) };
result
}
}
impl ComposablePermutation for Permutation {
// ...
}The consequences of using unsafe begin to show. Because our generic Permutation implements ComposablePermutation, and we have shown that permutation composition from different permutation groups may cause undefined behavior, Permutation::compose_into must be made unsafe at the trait level. Rust doesn’t allow us to only make Permutation’s implementation unsafe. Either all implementers must be made unsafe, or none at all. In a library about permutation composition, we have now forced our users to wrangle with unsafe for its most essential operation. Not just with Permutation::compose_into, but with all of their own implementations of ComposablePermutation!
“That is completely unfair!” You might say. “This is a small edge condition I don’t care about. I’m going to mark this trait method safe anyways.” Well, the Rust community generally has a zero-tolerance stance on undefined behavior; the last time someone wanted to mark an unsound method safe, it didn’t end very well.
The atomic ID approach
The second approach is to validate our base permutations upfront and use a private integer to associate them to a unique permutation group. This simplifies the test for permutation group membership to a cheap integer comparison. Internalizing how this approach works will be crucial to understanding the generativity approach. Rereading is encouraged.
use std::sync::atomic::{AtomicU64, Ordering::Relaxed};
pub struct PermGroup {
base_permutation_length: usize,
base_permutations: Vec<Permutation>,
id: u64,
}
static ID: AtomicU64 = AtomicU64::new(0);
impl PermGroup {
pub fn new(
base_permutation_length: usize,
base_permutation_mappings: Vec<Vec<usize>>,
) -> Result<Self, &'static str> {
for mapping in &base_permutation_mappings {
validate_permutation(mapping, base_permutation_length)?;
}
let id = ID.fetch_add(1, Relaxed);
Ok(Self {
base_permutation_length,
base_permutations: base_permutation_mappings
.into_iter()
.map(|mapping| Permutation(mapping.into_boxed_slice(), id))
.collect(),
id,
})
}
pub fn base_permutations(&self) -> &[Permutation] {
&self.base_permutations
}
}The implementation of PermGroup does not actually change much. As before, we check that all mappings from base_permutation_mappings are valid permutations of the same length before creating a new PermGroup. This time, we utilize a global AtomicU64 to uniquely identify the permutations in a permutation group, passing it as an integer to Permutation. The integer is guaranteed to be unique for Permutations among different PermGroups because we increment the identifier every call to PermGroup::new.
pub struct Permutation(Box<[usize]>, u64);
impl Permutation {
pub fn from_mapping_and_group(
mapping: Vec<usize>,
group: &PermGroup,
) -> Result<Self, &'static str> {
validate_permutation(&mapping, group.base_permutation_length)?;
let permutation = Self(mapping.into_boxed_slice(), group.id);
validate_permutation_group_membership(&permutation, &group.base_permutations)?;
Ok(permutation)
}
pub fn compose_into(&self, b: &Self, result: &mut Self) -> Result<(), &'static str> {
if self.1 != b.1 || b.1 != result.1 {
return Err("Permutations must come from the same permutation group");
}
for i in 0..result.0.len() {
// SAFETY: `self`, `b`, and `result` have the same ID.
// Therefore, they are members of the same group and
// can be composed.
unsafe {
*result.0.get_unchecked_mut(i) = *self.0.get_unchecked(*b.0.get_unchecked(i));
}
}
Ok(())
}
pub fn compose(&self, b: &Self) -> Result<Self, &'static str> {
let mut result = Self(vec![0; self.0.len()].into_boxed_slice(), self.1);
self.compose_into(b, &mut result)?;
Ok(result)
}
}Creating a new Permutation now requires a mapping and a PermGroup reference. Once the mapping is verified as both a valid permutation and a member of that permutation group, only then is a new Permutation created with that PermGroup’s identifier, as a “token” of its membership. We can no longer create Permutations willy-nilly from just a mapping because that would offer no guarantees about the uniqueness of its identifier.
The fruits of our labor are rewarded in Permutation::compose_into. The expensive permutation group membership test is performed exclusively during Permutation’s creation. When two permutations are composed, those same “tokens” are used to cheaply verify membership within the same permutation group. Hence, callers can safely assume permutation composition produces another permutation in the same permutation group without compromising efficiency.
This solution is likely to be considered good enough in industry—most practitioners would need a good reason to care more about this problem. However, if your interest is piqued, what would really be nice is an infallible yet zero-cost permutation composition operation—one that is guaranteed to be valid at compile-time and as fast as the unsafe approach. If you’re willing to go a small step farther, we arrive at…
The generativity approach
The big reveal: the generativity approach is equivalent to the atomic ID approach, except everything is done at compile-time. Generativity solves the fundamental problem thus far: the invariant of Permutation guarantees it is a valid permutation, but not that it is necessarily associated with a specific PermGroup.
Existing literature achieves generativity by sacrificing ergonomics and readability. They require wrapping all code in (often deeply nested) closures, warding off much of their interest in practice. We will spend the rest of this article examining Crystal Durham’s generativity crate, which utilizes a novel and highly experimental technique to achieve generativity without needing a closure. Later, we will show that the generativity crate is a zero-cost compile-time abstraction.
(Subtle-but-no-so-subtle foreshadowing: we will explore my own improvement to this technique in the next section)
use generativity::{Guard, Id, make_guard}
fn main() {
// Create a variable `guard` of type `Guard<'_>`
make_guard!(guard);
// Consume that `guard` into an `Id<'_>`
let id: Id<'_> = guard.into();
}generativity publicizes three things: Guard, Id, and make_guard. Invoking the make_guard macro creates a Guard<'_> with a let binding, an identifier that carries a guaranteed unique lifetime. This lifetime is not actually used as a lifetime in the usual sense. It exists solely to make each instance of Guard<'_> a unique type. This is not voluntary nor merely a suggestion; the following does not compile because make_guard’s lifetime uniqueness guarantee cannot be broken3.
fn unify_lifetimes<'a>(a: &Guard<'a>, b: &Guard<'a>) {}
make_guard!(a);
make_guard!(b);
// rejected: unique lifetimes cannot be unified (this
// is not the actual compiler error message)
unify_lifetimes(&a, &b);Id<'_> is like Guard<'_> except that it implements Copy and Clone while the latter does not. So, to create distributable copies of this identifier, you must consume a Guard<'_> into an Id<'_> using its From implementation. This is all that generativity exports.
With the generativity pattern in place, the body of PermGroup::new remains sound because it creates Permutations with the same lifetime identifier, making it unique among different PermGroups.
pub struct PermGroup {
pub struct PermGroup<'id> {
base_permutation_length: usize,
base_permutations: Vec<Permutation>,
id: u64,
id: Id<'id>
}pub fn new(
base_permutation_length: usize,
base_permutation_mappings: Vec<Vec<usize>>,
guard: Guard<'id>,
) -> Result<Self, &'static str> {
for mapping in &base_permutation_mappings {
validate_permutation(mapping, base_permutation_length)?;
}
let id = ID.fetch_add(1, Relaxed);
let id = guard.into();
Ok(Self {
base_permutation_length,
base_permutations: base_permutation_mappings
.into_iter()
.map(|mapping| Permutation(mapping.into_boxed_slice(), id))
.collect(),
id,
})
}Why is guard passed as an argument, and why isn’t make_guard creating it within the function body? This reveals generativity’s implementation caveat: a Guard<'id> can never escape the scope it was defined in. Think of creating a Guard<'id> as creating a reference to a local variable. No matter what, it is only valid inside of its enclosing scope.
So, instantiating two different permutation groups, for example, looks like this:
make_guard!(guard1);
make_guard!(guard2);
let first = PermGroup::new(..., guard1);
let second = PermGroup::new(..., guard2);
// rejected: `guard1` used after move
// let third = PermGroup::new(..., guard1);The purpose of Guard<'id> when Id<'id> already exists becomes clear when considering that third is rejected by the compiler. If PermGroup::new accepted an Id<'id>, two different permutation groups could be assigned the same Id<'id> because it implements Copy.
Okay, this is all fine and dandy, but how does this help improve permutation composition?
pub struct Permutation(Box<[usize]>, u64);
pub struct Permutation<'id>(Box<[usize]>, Id<'id>);Recall that every Id<'id> carries a unique lifetime among different PermGroup<'id>s. By combining Permutation with Id<'id> and a lifetime parameter, we create a collection Permutation<'id>s whose types are the same within a PermGroup<'id> but distinct from permutations within other PermGroups<'id2>s. Our permutation composition function takes in the same type Self for all arguments—it follows that Permutation<'id>s from different permutation groups cannot be composed as they are not the same type, and Permutation<'id>s from the same permutation group can be composed as they are the same type. This is the essence of the generativity pattern, enforced at compile-time.
Behold: a permutation composition function that is unchecked, infallible, and safe. The full implementation is here.
pub fn compose_into(&self, b: &Self, result: &mut Self) -> Result<(), &'static str> {
if self.1 != b.1 || b.1 != result.1 {
return Err("Permutations must come from the same permutation group");
}
pub fn compose_into(&self, b: &Self, result: &mut Self) {
for i in 0..result.0.len() {
// SAFETY: `self`, `b`, and `result` are members of the
// same group and can be composed.
unsafe {
*result.0.get_unchecked_mut(i) = *self.0.get_unchecked(*b.0.get_unchecked(i));
}
}
Ok(())
}Let us informally prove generativity’s equivalence to the atomic ID approach:
- In the atomic ID approach, unique integer identifiers are created à la
ID.fetch_add(1, Relaxed). This directly parallelsmake_guard!(guard), which creates a uniqueGuard<'id>identifier. - The unique integer identifier is then stored inside a primitive
u64. This implementsCopyand it is distributed among the input base permutations to associate each one with its permutation group. Similarly,Id<'id>serves this purpose. - The unique integer identifier is used to test permutation group membership during permutation composition, erroring if not the case. The generativity pattern directly embeds the same test into the type system.
It would be irresponsible for me to advertise the generativity crate as a perfect solution barring its implementation caveat. Yes, the implementation caveat is its only functional limitation, but there are some developer experience problems to consider.
- Although there’s only a single line marked unsafe in our
Permutation<'id>example, its soundness is now much harder to justify. It is on the developer to prove that'iduniquely associates permutations to their permutation group; any mishandling could easily make the whole thing unsound (i.e. ifPermGroup::newtook anId<'id>instead of aGuard<'id>). - The
'idlifetime, like all other lifetimes, is pervasive. Data structures that wish to storeGuard<'id>orId<'id>, or any other data structure that storesGuard<'id>orId<'id>, must have a lifetime annotation. Butmake_guardis typically invoked at the outermost scope, and will likely have to be passed through many types, so the number of lifetime annotations is amplified. - Some APIs require types to satisfy
'static. For example, the closure passed tothread::spawnmust satisfy'static, making it impossible to return aPermutation<'id>. The workaround is usually an inconvenient band-aid; in this case the standard library offersthread::scopeto borrow non-'staticdata in a thread. - The compiler errors from misusing
generativitydon’t provide the location of the error. They are generally confusing, even when you know howgenerativityinternally works.
The atomic ID approach shares only the first problem. Given your use case, it might be what you want.
The fundamental purpose
Notice how different instances of Permutation<'id> masquerade as separate types even though they have the same underlying data representation. In Rust, 'id is known as a branded lifetime, or more generally, a type brand. The first principles of type branding date back at least to the work of John Launchbury and Simon Peyton Jones on the ST monad in Haskell (section 2.5.2) in 1995. Aria Desires’ master’s thesis (section 6.3) brought this into the context of Rust in 2015, coining lifetime branding in Rust with the term “generativity.” The more recent GhostCell paper by Joshua Yanovski and others utilized generativity to present interior mutability as a zero-cost abstraction in 2021.
This segues into an important point. The fundamental purpose of the generativity pattern is not necessarily to improve performance, but to statically require that individual values come from or refer to the same source. The performance benefits are a symptom of this requirement. I like to informally think of it as a stronger form of ownership.
For an alternative perspective, Aria Desires’ master’s thesis explores this idea with a concept called a BrandedVec. When the ith element of an ordinary vector vec is accessed through &vec[i], a run-time check is performed to see if i is in bounds. If not, then the program will panic. However, in many situations we know that the indices are always in bounds; one such case regards the append-only vector, the BrandedVec. All elements pushed to this type of vector are forever valid. Leveraging this fact, the push operation returns the index of the pushed element so it can later be used to soundly perform unchecked indexing.
If we wanted to mark the unchecked indexing operation safe, this returned index can’t be an ordinary usize. Bad actors may provide their own usize instead of one returned from the push operation. This returned index can’t be a newtyped usize either. The problem with this is a microcosm of the problem with our initial Permutation example: different indices from different append-only vectors may be used to unsoundly index one another. To make our accesses safe, the solution is to lifetime brand the returned indices to statically associate them with vec—the generativity pattern.
As hinted to beforehand, generativity has traditionally only been achieved through the use of a closure. The GhostCell paper includes this following example, taken from its inspired adaption of BrandedVec.
let vec1: Vec<u8> = vec![10, 11];
let vec2: Vec<u8> = vec![20, 21];
BrandedVec::new(vec1, move |mut bvec1: BrandedVec<u8>| {
bvec1.push(12);
let i1 = bvec1.push(13);
let _idx = bvec1.get_index(0).unwrap();
BrandedVec::new(vec2, move |mut bvec2: BrandedVec<u8>| {
let i2 = bvec2.push(22);
println!("{:?}", bvec2.get(i2)); // No bound check! Prints 22
*bvec2.get_mut(i2) -= 1; // No bound check!
println!("{:?}", bvec2.get(i2)); // Prints 21
println!("{:?}", bvec1.get(i1)); // Prints 13
// rejected: i1 is not an index of bvec2
// println!("{:?}", bvec2.get(i1));
});
});Each BrandedVec created from a Vec receives its own lifetime brand within each closure4. In terms of ergonomics, it’s not exactly your Friendly Neighborhood Spider-Man.
But through the generativity crate, we eliminate the rightward drift, changing just nine lines of BrandedVec’s implementation. The API now appears less foreign and more Rust-like.
let vec1: Vec<u8> = vec![10, 11];
let vec2: Vec<u8> = vec![20, 21];
make_guard!(guard1);
let mut bvec1 = BrandedVec::new(vec1, guard1);
bvec1.push(12)
let i1 = bvec1.push(13);
let _idx = bvec1.get_index(0).unwrap();
make_guard!(guard2);
let mut bvec2 = BrandedVec::new(vec2, guard2);
let i2 = bvec2.push(22);
println!("{:?}", bvec2.get(i2)); // No bound check! Prints 22
*bvec2.get_mut(i2) -= 1; // No bound check!
println!("{:?}", bvec2.get(i2)); // Prints 21
println!("{:?}", bvec1.get(i1)); // Prints 13
// rejected: i1 is not an index of bvec2
// println!("{:?}", bvec2.get(i1))Our digression in bringing up this comparison has an ulterior motive. The original closure technique bears the exact same implementation caveat with generativity: nothing declared inside of the closure can escape it. make_guard effectively does the same thing as wrapping the rest of the function in an immediately invoked closure, and is no less capable than the closure technique.
Why the implementation caveat?
Let us offer another perspective as to why Guard<'id> cannot escape its defining scope. StackOverflow user rodrigo points out that you can achieve something similar to generativity using an anonymous unit struct and a macro to create the permutation group. Successive calls to this macro create permutation groups branded by this newly generated unit struct. In the context of our Permutation example, example usage looks like this. The full implementation is here.
#[macro_export]
macro_rules! new_perm_group {
($len:expr, $mappings:expr) => {{
let len = $len;
let mappings = $mappings;
struct InvariantToken;
// SAFETY: private API, only used in this macro.
unsafe {
$crate::PermGroup::<InvariantToken>::new(len, mappings)
}
}};
}let first_perm_group = new_perm_group!(4, vec![vec![1, 2, 0, 3]]).unwrap();
let second_perm_group = new_perm_group!(3, vec![vec![2, 0, 1]]).unwrap();
let first_perm = &first_perm_group.base_permutations()[0];
let second_perm = &second_perm_group.base_permutations()[0];
// rejected: `first_perm` and `second_perm` are not the same type
// first_perm.compose(second_perm);The flaw is quite subtle. The macro constructor creates a token per-call-site instead of per-owner. Every expression results in a particular type; if the same macro is run more than once, it will produce the same type, even if it is unique to the expression. This can be exploited to give multiple owners the same brand. To exemplify:
let first = (4, vec![vec![1, 2, 0, 3]]);
let second = (3, vec![vec![2, 0, 1]]);
let mut perm_groups = vec![];
for (len, mappings) in [first, second] {
// I expanded the macro to make it easier to understand!
// perm_groups.push(new_perm_group!(len, mappings).unwrap());
perm_groups.push({
let len = len;
let mappings = mappings;
struct InvariantToken;
// SAFETY: private API, only used in this macro.
unsafe {
crate::PermGroup::<InvariantToken>::new(len, mappings)
}
}.unwrap());
}
let first_perm = &perm_groups[0].base_permutations()[0];
let second_perm = &perm_groups[1].base_permutations()[0];
// not rejected, UB!
first_perm.compose(second_perm);We have just invoked undefined behavior from safe user-facing code. This is unsound without question, and there is no point in endorsing this approach.
There is a remedy: combine InvariantToken with a locally-scoped lifetime, as illustrated in binarycat’s crate typetoken. This only creates a strictly less capable version of generativity. There is no point in endorsing this approach either.
If the above code were possible with generativity, 'id could escape the scope and assign all elements of the vector the same lifetime brand. We would have the exact same unsoundness problem, thus we cannot use a loop to create a dynamic number of PermGroup<'id>s.
How does generativity work?
At this point a good part of my readers are itching to know what makes the generativity crate so magical compared to the age-old closure technique. The suspense is probably killing you. Or more likely putting you to sleep. We will introduce the inner workings of generativity top-down. I will first present my own minimal rewrite of the generativity crate, called min_generativity. Then, we will comprehensively walk through how each part of it works.
min_generativity
use std::marker::PhantomData;
pub type Id<'id> = PhantomData<fn(&'id ()) -> &'id ()>;
pub struct Guard<'id>(pub Id<'id>);
impl<'id> From<Guard<'id>> for Id<'id> {
fn from(guard: Guard<'id>) -> Self {
guard.0
}
}
pub struct LifetimeBrand<'id>(PhantomData<&'id Id<'id>>);
impl<'id> LifetimeBrand<'id> {
pub fn new(_: &'id Id<'id>) -> Self {
LifetimeBrand(PhantomData)
}
}
impl<'id> Drop for LifetimeBrand<'id> {
fn drop(&mut self) {}
}
#[macro_export]
macro_rules! make_guard {
($name:ident) => {
let branded_place: $crate::Id = std::marker::PhantomData;
let lifetime_brand = $crate::LifetimeBrand::new(&branded_place);
let $name = $crate::Guard(branded_place);
};
}Before we get started, let’s get some low hanging fruit out of the way. We can verify that min_generativity is zero-cost: every single type is some form of PhantomData, a zero-sized type that is optimized away at compile-time. However, there is a sharp corner: we create a reference to a PhantomData in make_guard, and references to zero-sized types are perhaps surprisingly not zero-sized due to some idiosyncrasies. Thus, we cannot prove min_generativity is zero-cost as Rust lacks a specification for optimization behavior. I claim that in practice this is the case the overwhelming majority of the time. The reference: is never used anywhere, is associated with an unused variable (lifetime_brand), and has no Drop impl. Even at the most basic optimization level, rustc is smart enough to no-op everything.
Note that min_generativity benevolently assumes that library users will only use make_guard to construct Id<'id> and Guard<'id>, as both are public types with public field visibility. The actual generativity crate privatizes Id<'id> (via a newtype) and Guard<'id> and marks their constructors unsafe, hidden within make_guard. Such was omitted to be concise.
The first part
use std::marker::PhantomData;
pub type Id<'id> = PhantomData<fn(&'id ()) -> &'id ()>;If you’ve only used PhantomData when the compiler has told you to, this certainly looks nonsensical. The purpose of Id<'id> as we saw earlier is to carry a unique lifetime brand among different PermGroup<'id>s, but aren’t lifetimes already unique? What’s the deal?
In Rust, variance determines whether you can substitute one lifetime for another. If you have a longer lifetime, Rust lets you use it where a shorter one is expected. This is also known as subtyping. Normally this is good—subtyping introduces static analysis that allows for more programs to compile—but in our case this automatic substitution works against our favor. If an Id<'id> can be tied to a lifetime other than its lifetime brand, we lose. So, the unique lifetime 'id must have no subtyping relation with other lifetimes; 'id is what’s called an invariant lifetime.
The contemporary usage of the word “invariant” by Rustaceans has two meanings: one as a type-level guarantee (a noun), and one as a no-subtyping relation (an adjective). Invariant generally means something that cannot change or must be fixed to a specific value. Both meanings refer to this same general concept. We’ve been working with the first meaning so far, but for the rest of this article we’ll switch to the second one.
To make 'id invariant, we take advantage of a fundamental constraint with function pointer types. When you have fn(&'id T) -> &'id T, the caller provides a reference with lifetime 'id and expects to get back a reference with that same lifetime 'id. If Rust allowed the function pointer type to accept a longer lifetime but return a shorter one, or vice versa, it would break this explicit contract. You might pass in a reference that lives for ten seconds but get one back that lives for five seconds, creating a dangling pointer. Function pointer types with the same lifetime in the input and output positions force that lifetime to be invariant. No substitution allowed.
Of course, we don’t actually want to store a function pointer at run-time. We only utilize it to make 'id invariant at compile-time. The language provides PhantomData to enable fine-grained control over variance. In this case it tells the compiler to pretend like it holds a function pointer while not actually taking up any space.
When I first learned how to use PhantomData to indicate variance I couldn’t help but think of it as an obnoxiously leaky abstraction. There is a movement to make it a bit more ergonomic by introducing custom variance newtypes into the standard library, i.e. PhantomInvariantLifetime. Sure enough, the status quo of PhantomData has been considered “something of a failure.”
The second part
pub struct Guard<'id>(pub Id<'id>);
impl<'id> From<Guard<'id>> for Id<'id> {
fn from(guard: Guard<'id>) -> Self {
guard.0
}
}The entire implementation of Guard<'id> is a newtype around Id<'id>. The established difference being that Guard<'id> doesn’t implement Copy or Clone. We provide a From implementation to consume a Guard<'id> into an Id<'id> to create distributable copies of the lifetime brand, as we saw earlier.
The third part
pub struct LifetimeBrand<'id>(PhantomData<&'id Id<'id>>);
impl<'id> LifetimeBrand<'id> {
pub fn new(_: &'id Id<'id>) -> Self {
LifetimeBrand(PhantomData)
}
}
impl<'id> Drop for LifetimeBrand<'id> {
fn drop(&mut self) {}
}
#[macro_export]
macro_rules! make_guard {
($name:ident) => {
let branded_place: $crate::Id = std::marker::PhantomData;
let lifetime_brand = $crate::LifetimeBrand::new(&branded_place);
let $name = $crate::Guard(branded_place);
};
}It turns out that disabling lifetime subtyping is not enough. While Rust believes it’s unsound to freely resize 'id, there’s nothing that constrains where 'id should come from. Consider the following system:
fn unify_lifetimes<'id>(_: &Id<'id>, _: &Id<'id>) {}
let id1: Id<'id1> = PhantomData;
let id2: Id<'id2> = PhantomData;
unify_lifetimes(&id1, &id2);The constraint solver realizes there is no logical contradiction with the obvious solution of 'id2 = 'id1, and it allows this program to compile. We need to uniquely tie 'id1 and 'id2 to their respective declaration sites to prevent Rust from unifying them.
After make_guard creates branded_place and generates an invariant lifetime 'id, we are now armed with the knowledge required to examine how LifetimeBrand ensures it is non-unifiable. It takes the approach of establishing distinct lower and upper bounds for 'id, highlighting the need for a macro with protected hygiene to prevent these bounds from potentially being manipulated.
Notice that LifetimeBrand carries the phantom type &'id Id<'id> (to avoid actually storing the reference). The existence of LifetimeBrand’s Drop impl means this borrowed data could potentially be used at the end of the scope, delegating special analysis called the drop check. The drop check forces the compiler to extend 'id to live at the point where lifetime_brand is dropped, constituting our lower bound. The actual Drop impl is purposefully left blank.
An important guarantee from the compiler is that local variables in a scope are dropped in the opposite order they are defined. Now we must prevent successive make_guard invocations in the same scope from unifying with the first invocation whose lifetime lives the longest. We are left with a need to upper-bound 'id, and this is done by tying 'id to the borrow of what created it. So, any expansion of 'id would mean branded_place’s borrow of lifetime 'id wouldn’t live long enough when it is dropped.
If you still find it confusing, I encourage you to work out rustc’s error message in this example. I also encourage you to play around with this code snippet to see what compiles and what doesn’t. I’ve found this exercise illuminating. Another tip to help you understand is to remember the pithy saying that lifetimes are descriptive, not prescriptive.
Verifying soundness
It is easy to verify that generativity is sound.
make_guard!(id1);
make_guard!(id2);
assert_eq!(id1, id1);
assert_eq!(id2, id2);
// rejected: `branded_place` does not live long enough
// assert_eq!(id1, id2);At the time of writing, this test case passes. However, generativity’s vice is that it relies on internal behavior from the drop check analysis, the precise rules of which have historically been ill-defined and subject to change. In theory, sufficiently advanced analysis would be able to see that dropping lifetime_brand doesn’t require 'id to live because its Drop impl is empty, destroying the uniqueness guarantee we have created.
Pertaining to our concerns, any weakening of the drop check forcing captured lifetimes to live will most likely be opt-in, based on the direction of the “drop check eyepatch” RFC. It introduces the unsafe #[may_dangle] attribute which relaxes this requirement. #[may_dangle] opts-in a struct’s Drop impl to say, “I don’t access a generic parameter, so it can be dropped before I run.” Drop check eyepatch was introduced as a hacky refinement over “unguarded escape hatch,” which permitted high-priority collections like Vec<&T> to drop despite the &T borrow being invalidated beforehand.
Here are some famous last words. Drop check eyepatch was accepted nine years ago, yet stabilization is still opposed. There are too many subtle gotchas with respect to the drop check that have been found to be too much of a footgun even for an internal compiler feature. It has resulted in unsoundness multiple times. The stable analysis is deliberately conservative for this reason. To quote from the Rustonomicon’s explanation of #[may_dangle], “it is better to avoid adding the attribute.”
The existing avenue of improvement clarifies the semantics but still holds that this behavior will be opt-in. Hence, we can strengthen our confidence that the livelihood requirements for generativity will remain sound.
There are two other soundness concerns that are unlikely to be problematic but are still brought up in brief:
generativityrelies on an unused variable,lifetime_brand, to impact borrow checking and the drop check. If support for unused variable analysis is ever removed, thenscopeguard, a crate with hundreds of millions of downloads, would break, and Rust is very careful not to break existing code.scopeguardalso relies on theDropimpl of an unused variable. Additionally, with the drop check, borrow checking must also run by virtue oflifetime_brand’sDropimpl, which could possibly access the borrow5.- In the ultra rare case where
generativityis used in a divergent function, the drop checker will realize thatDropnever runs and skip the drop check entirely. Special care is required in this case to uphold soundness. - It may still be hard to trust the delicate configuration of upper and lower bounding the generated lifetime. With non-lexical lifetimes stabilized in 2022 as the second edition of the borrow checker, the only planned next iteration is Polonius, the implementation of which currently passes the aforementioned test case. I haven’t given it much thought, but proving
generativity’s soundness with Polonius’ formal model of the borrow checker would be a fun project (to me at least).
Language support
We can no longer ignore the elephant in the room with the make_guard macro: it looks ugly. It injects local variables into the current scope, and we saw this was necessary in the statement-position to prevent the lifetime bounding tricks from being manipulated. For a while there was no resolution, until just a few months ago when the experimental super let feature was introduced to extend the lifetimes of block-scoped variables. By creating a block scope, expression-position make_guard is made possible on nightly Rust.
#![feature(super_let)]
// ...
#[macro_export]
macro_rules! make_guard {
($name:ident) => {
let branded_place: $crate::Id = std::marker::PhantomData;
let lifetime_brand = $crate::LifetimeBrand::new(&branded_place);
let $name = $crate::Guard(branded_place);
};
() => {{
super let branded_place: $crate::Id = std::marker::PhantomData;
super let lifetime_brand = $crate::LifetimeBrand::new(&branded_place);
$crate::Guard(branded_place)
}};
}
fn main() {
make_guard!(guard);
let guard = make_guard!();
}Furthermore, there are preliminary ideas that would allow make_guard to be a function instead of a macro. The feedback for super let has so far been positive, so once the semantics are ironed out I think efforts to stabilize this feature will be underway.
My last contribution to this discussion is some wishful thinking about first-class language support for generativity. The troubles with unique lifetime branding stem from the fact that Rust offers no way to prevent lifetimes from unifying. So, I propose the #[nonunifiable] lifetime attribute. It would allow lifetimes to declaratively guarantee non-unifiability without having to resort to generativity’s lifetime bounding tricks. #[nonunifiable] is not intended to indicate variance—that’s the job of PhantomData. For the permutation example, first-class language support from the compiler would look like this. The full implementation is here.
pub struct PermGroup<#[nonunifiable] 'id> {
base_permutation_length: usize,
base_permutations: Vec<Permutation<'id>>,
id: PhantomData<fn(&'id ()) -> &'id ()>
}
pub struct Permutation<'id>(Box<[usize]>, PhantomData<fn(&'id ()) -> &'id ()>);First-class language support is also the perfect excuse to improve the confusing compiler errors:
let first = PermGroup::new(4, vec![vec![1, 2, 0, 3]]).unwrap();
let second = PermGroup::new(3, vec![vec![2, 0, 1]]).unwrap();
let first_perm = &first.base_permutations()[0];
let second_perm = &second.base_permutations()[0];
first_perm.compose(second_perm);error[E0308]: mismatched types
--> src/main.rs:9:23
|
6 | let first_perm = &first.base_permutations()[0];
| ---------- binding `first_perm` declared here with nonunifiable lifetime `’1`
7 | let second_perm = &second.base_permutations()[0];
| ----------- binding `second_perm` declared here with nonunifiable lifetime `’2`
8 |
9 | first_perm.compose(second_perm);
| ------- ^^^^^^^^^^^ expected `Permutation<'1>`, found a different `Permutation<'2>`
| |
| arguments to this method are incorrect
|
= note: expected reference `&Permutation<'1>`
found reference `&Permutation<'2>`
= note: `Permtuation<'1>` and `Permutation<'2>` look like similar types, but are distinct because they carry `#[nonunifiable]` lifetimesJack (one of this article’s peer reviewers) and I discussed what first-class language support to remove the lifetime parameter and allow Guard to escape its scope could look like. Unfortunately, we came to the conclusion that such a system would be equivalent to the problem case described in Why the implementation caveat?. Creating an arbitrary number of branded types in a loop during run-time would require deep changes to the type system.
Maybe #[nonunifiable] will have an unexpected use case that would make it practical, or maybe not. I’m not going to pretend like I’ve figured out all of the semantics. The point is to get my thoughts up in the air.
Benchmarks
No comparison would be complete without a benchmark. Yes, the point of the generativity pattern is more fundamental than just speed, but I know what people want. I statically generated two random length-fifteen permutations and wrote a Criterion benchmark for all five approaches to permutation composition.
| Benchmark Name | Time (ns) |
|---|---|
| 1-slice | 14.805 |
| 2-newtype | 4.257 |
| 4-atomic_id | 3.940 |
| 5-generativity | 3.604 |
| 3-unsafe_trait | 3.602 |
Empirically, this validates all of my observations. The naive 1-slice is the slowest because it checks every permutation for complete validity during composition. 2-newtype removes most of the validation overhead. Admittedly this is good enough; again, from a practical standpoint, you would only care about the other solutions if you could prove that permutation composition was the bottleneck. 4-atomic_id replaces the validation with a single integer comparison, making it marginally faster, likely because it avoids dereferencing. Finally, 5-generativity and 3-unsafe_trait emerge the fastest because they avoid validation entirely, and I have also verified that the generated machine code is identical. The important difference: 3-unsafe_trait marks permutation composition unsafe while 5-generativity does not.
Conclusion
Truthfully I don’t have many final thoughts. I just needed a transition to end this article. I suppose my primary conclusion is that this article has gotten far longer than I had originally planned 😛.
I don’t think this is a bad thing; its comprehensiveness more than makes up for it. The hidden agenda was to survey design patterns and write about Rust code I thought were interesting, culminating with the generativity pattern, which shows us how to take advantage of the type checker’s power in a non-obvious manner.
This concludes my first educational write-up on my blog. I came into this topic with surface level understandings of what generativity, PhantomData, and the drop check are and how they work. I was not expecting this to take five weeks of meticulous research and writing throughout my summer break in undergrad. I was entirely unprepared for how interesting the full story would be.
Thank you for reading this far :-). Until next time!
Footnotes
-
Yes, I will eventually get to them. You just need to keep reading. ↩
-
The center stickers don’t actually move, and thus can be ignored, so the illustrated turn is traditionally simplified to a permutation forty-eight elements long. ↩
-
This lifetime is not technically unique. You could unify it with another lifetime in a similar function call:
fn unify_lifetimes<'id>(impostor: &'id (), guard: &Guard<'id>) { ... }. The lifetime is only unique among the providedId<'id>andGuard<'id>types, so as long as your code only trusts lifetimes carried by those types it will be sound. ↩ -
Rust doesn’t have rank-2 polymorphism, so we need to replicate it using a closure with a Higher-Rank Trait Bound. The type signature of the closure passed to
BrandedVec::newisinner: impl for<'id> FnOnce(BrandedVec<'id, T>) -> R, and this just means every call toinnermust be prepared to handle an argument with any possible lifetime. Within a single function the compiler has perfect information, but callinginnerinsideBrandedVec::newtricks the borrow checker. Since it doesn’t (and will likely never) do interprocedural analysis, it conservatively sees every call toinneras producing an opaque lifetime that can’t be unified with any other. To avoid any relation with an existing lifetime, a fresh new lifetime is statically generated for every call toBrandedVec::new, our lifetime brand forBrandedVec<'id, T>. This is just a brief overview of a well-investigated topic. Repeating for convenience, further reading is encouraged here (section 6.3) and here (section 2.2.1). ↩ -
Unreachable code on the other hand is not borrow checked because it simply wasn’t a priority. ↩